ML: Classificação, Regressão Linear e Clusterização
10 Aug 2019Processo de Classificação
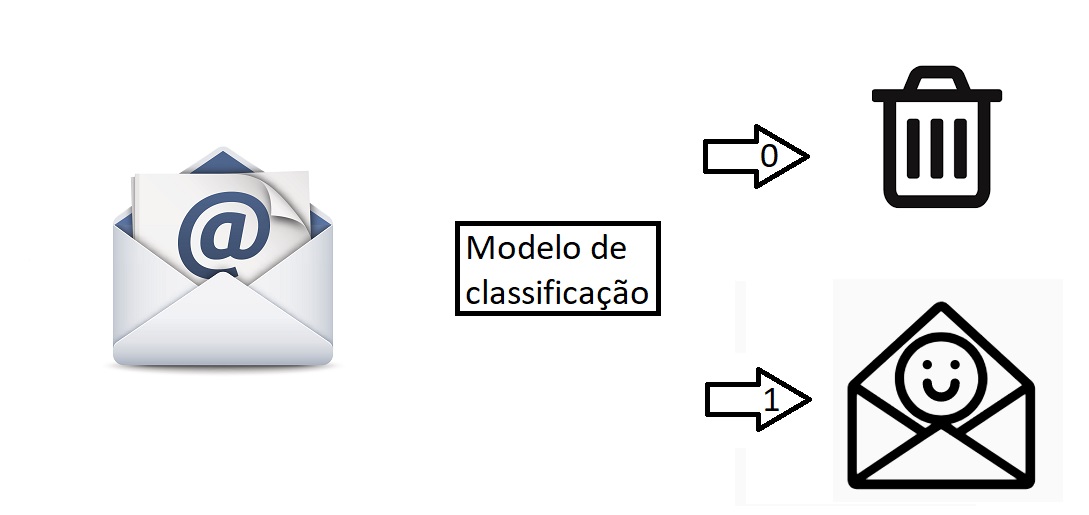
O processo de classificação tem como objetivo identificar a categoria à qual uma nova entrada de dados pertence, com base em um conjunto de dados históricos.
Um exemplo comum é o classificador de spam, que, com base em registros anteriores contendo palavras-chave frequentemente usadas em e-mails de spam, categoriza novos e-mails como spam ou não spam.
Processo de Regressão
Ao contrário da classificação, no processo de regressão, o objetivo é prever comportamentos futuros com base em critérios conhecidos. Um exemplo seria prever a demanda por guarda-chuvas com base na quantidade de chuva, permitindo uma melhor organização do estoque e pedidos.
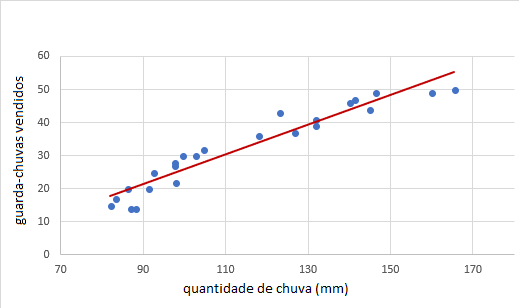
No exemplo acima, abordamos um modelo de Regressão Linear Simples, mas existem modelos mais complexos, como Regressão Linear Múltipla e Regressão Logística, que exploraremos em futuras postagens.
Correlação entre Variáveis
Para determinar se duas variáveis estão correlacionadas, basta plotar um gráfico e, de forma intuitiva, é possível identificar padrões.
Na imagem a seguir, da direita para a esquerda, apresentamos exemplos de:
- Forte correlação positiva
- Forte correlação negativa
- Correlação positiva moderada
- Correlação negativa moderada
- Ausência de correlação

Correlação não Implica Causalidade
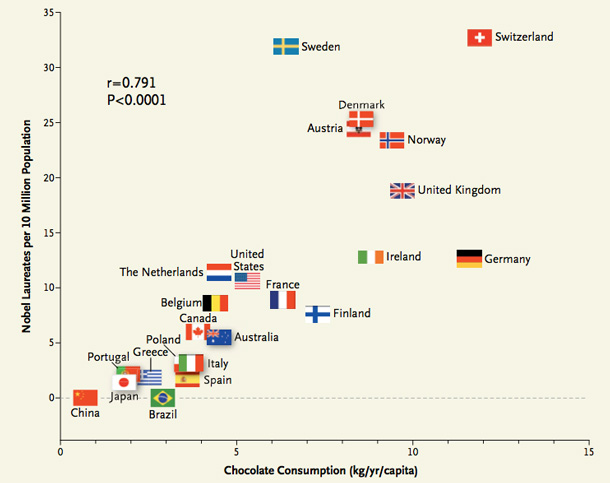
Uma máxima na estatística é que "Correlação não implica causalidade", o que significa que não podemos tirar conclusões definitivas com base apenas em correlações. É aqui que o conhecimento de domínio desempenha um papel crucial.
Um exemplo clássico é a relação entre o consumo de chocolate e o número de prêmios Nobel por país.
O que não foi considerado e passou despercebido foram outras variáveis importantes. Por exemplo, o fato de que existe uma correlação entre a quantidade de chocolate consumida e o número de prêmios Nobel pode ser influenciado por outros fatores, como o nível de renda, o grau de educação e o poder aquisitivo das pessoas para comprar chocolate. Além disso, o tamanho do país desempenha um papel significativo, uma vez que os EUA têm uma produção científica muito alta, mas também uma população muito maior em comparação com a Noruega. Isso exemplifica a importância de compreender o contexto e as nuances do cenário em que os dados são analisados.
Outro exemplo bizarro é a aparente relação entre o número de filmes de Nicolas Cage e as mortes por afogamento em piscinas.
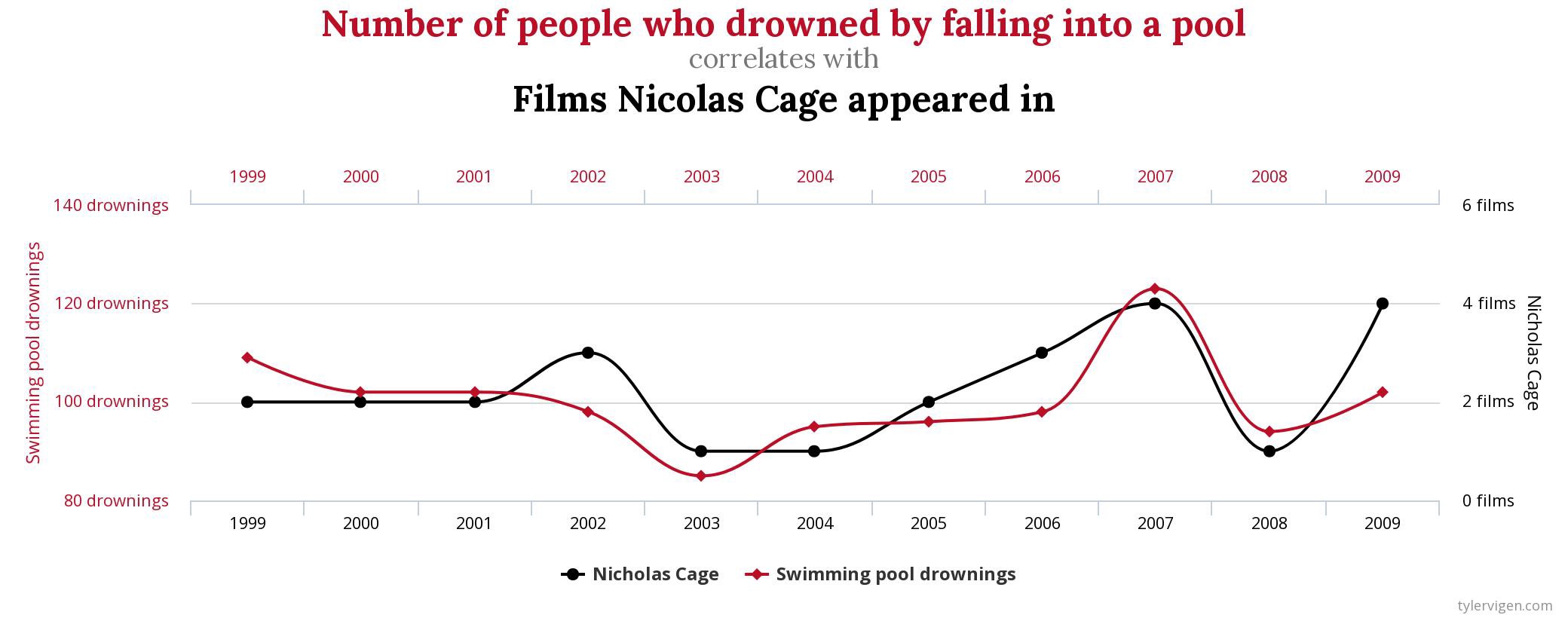
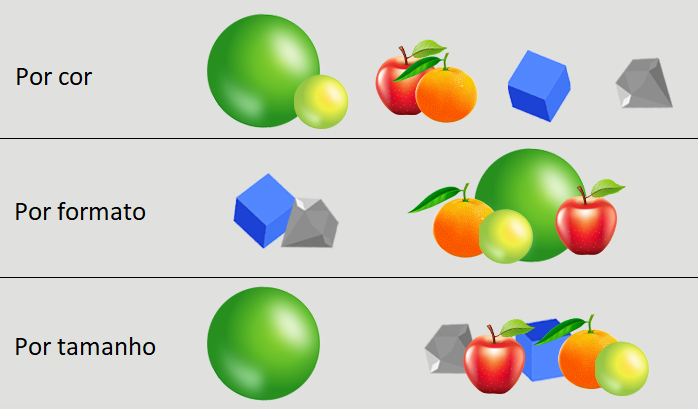
Processo de Clusterização
Na aprendizagem não supervisionada, temos o processo de clusterização. Nesse caso, os algoritmos procuram características semelhantes e agrupam os dados em pequenos grupos, sendo o número de grupos um parâmetro que precisa ser especificado manualmente.
Para ilustrar, considere a organização de produtos em um supermercado, que pode ser feita com base em diferentes critérios, como preço, marca, uso, data de validade, cor, etc.
Alguns métodos comuns de clusterização incluem:
- Baseado no centróide
- Baseado na conectividade
- Baseado na densidade
- Baseado em métodos probabilísticos